本文是读《深入剖析 Kubernetes》的笔记
在很久之前写过几篇关于 Docker 的文章,当时也正处于自己接触 Docker 不久,后来一直没在实际环境中使用过。最近公司要搞一套服务,需要使用 Kubernetes 来编排所以的容器。然后就重新拾起 Docker 的内容,最近也在学习 Kubernetes,最近在看极客时间的《深入剖析Kubernetes》,感兴趣的可以从下面地址购买。

在之前知道 Docker 容器使用了 Namespace 和 Ggroups 技术,但是对于这两个东西具体是什么,还真没搞清楚过。真心推荐极客时间的这么课,还是非常不错的。
容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造一个”边界“。
对于Docker等大多数Linux容器来说,Cgroups是用来制造约束的主要手段,Namespace则是用来修改进程试图的主要方法。
Namespace
namespace 是 Linux 内核用来隔离内核资源的方式。通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。
Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。
使用过 Docker 的应该知道,如果我们使用 docker exec -it 进入容器,然后使用ps命令,你会看到以下信息:
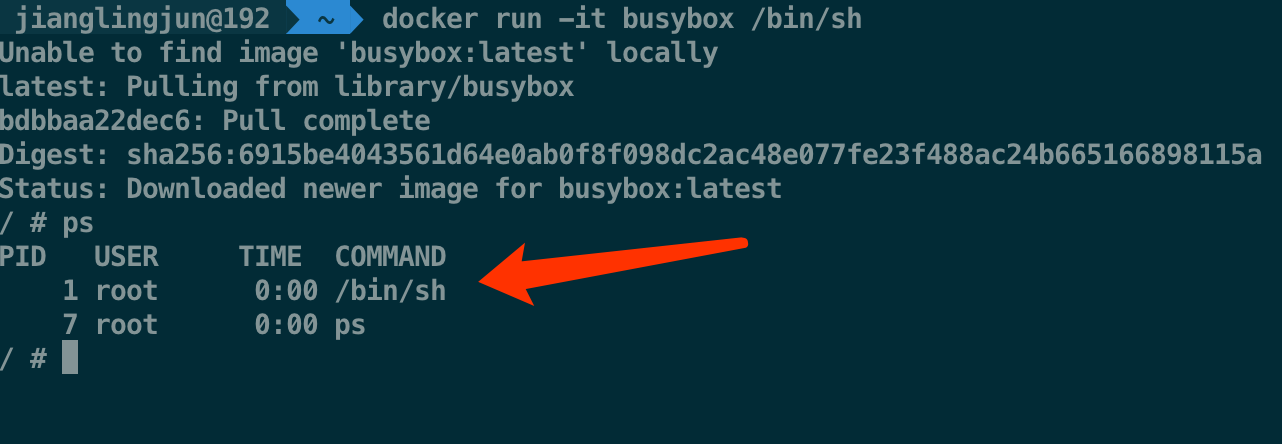
我们可以看到这个容器内部的第一号进程,容器已经被 Docker 隔离了。那docker是如何在Linux宿主机上实现这个的呢?这个使用的就Linux的Namespace技术,而且启动的并没有重新创建一个进程,只是使用了一个障眼法。
在我们启动容器的时候,Linux系统会创建一个进程,比如 PID = 100,使用 Namespace 技术后,会对这个 PID 进行掩饰,编程 PID = 1。
Namespace 技术知识 Linux 创建新进程的一个可选参数。在 Linux 系统中创建线程的系统调用的是 clone():
1 | int pid = clone(main_function, stack_size, SIGCHLD, NULL); |
Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。
这就是Linux容器最基本的实现原理。所以从这里看出,容器其实就是一个使用宿主机资源的进程而已。
通过上面的简单介绍,我们知道,容器只是运行在宿主机上的一种特殊进程,那么多个容器之间使用的还是宿主机的操作系统内核。这就导致你不能在Windows宿主机上运行Linux内核,或者在低版本Linux上运行高版本Linux内核。
Cgroups
Linux Cgroups 的全称是 Linux Control Group,它最主要的作用就是限制一个进程组能够使用资源的上限,包括CPU、内存、磁盘、网络带宽等等。
我们可以使用 mount -t cgroup 来查看linux 系统的文件系统,这些在系统/sys/fs/cgroup 下的资源,都是可以被 Cgroups 进行限制的资源种类。

在Docker 中,可以在启动的时候带上参数,这样来限制容器的资源:
1 | docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash |
然后我们可以在宿主机上查看这些资源文件的参数,这样一位这只能使用20%的CPU。


