在项目中,事务可以有效的防止在程序出错时,对于数据的错误修改,回滚到修改之前。
spring事务和数据库事务一样,都有四个特性(ACID):
原子性(Atomicity):事务是一个原子操作,由一系列动作组成。事务的原子性确保动作要么全部完成,要么完全不起作用;
一致性(Consistency):一旦事务完成(不管成功还是失败),系统必须确保它所建模的业务处于一致的状态,而不会是部分完成部分失败。在现实中的数据不应该被破坏;
隔离性(Isolation):可能有许多事务会同时处理相同的数据,因此每个事务都应该与其他事务隔离开来,防止数据损坏;
持久性(Durability):一旦事务完成,无论发生什么系统错误,它的结果都不应该受到影响,这样就能从任何系统崩溃中恢复过来。通常情况下,事务的结果被写到持久化存储器中;
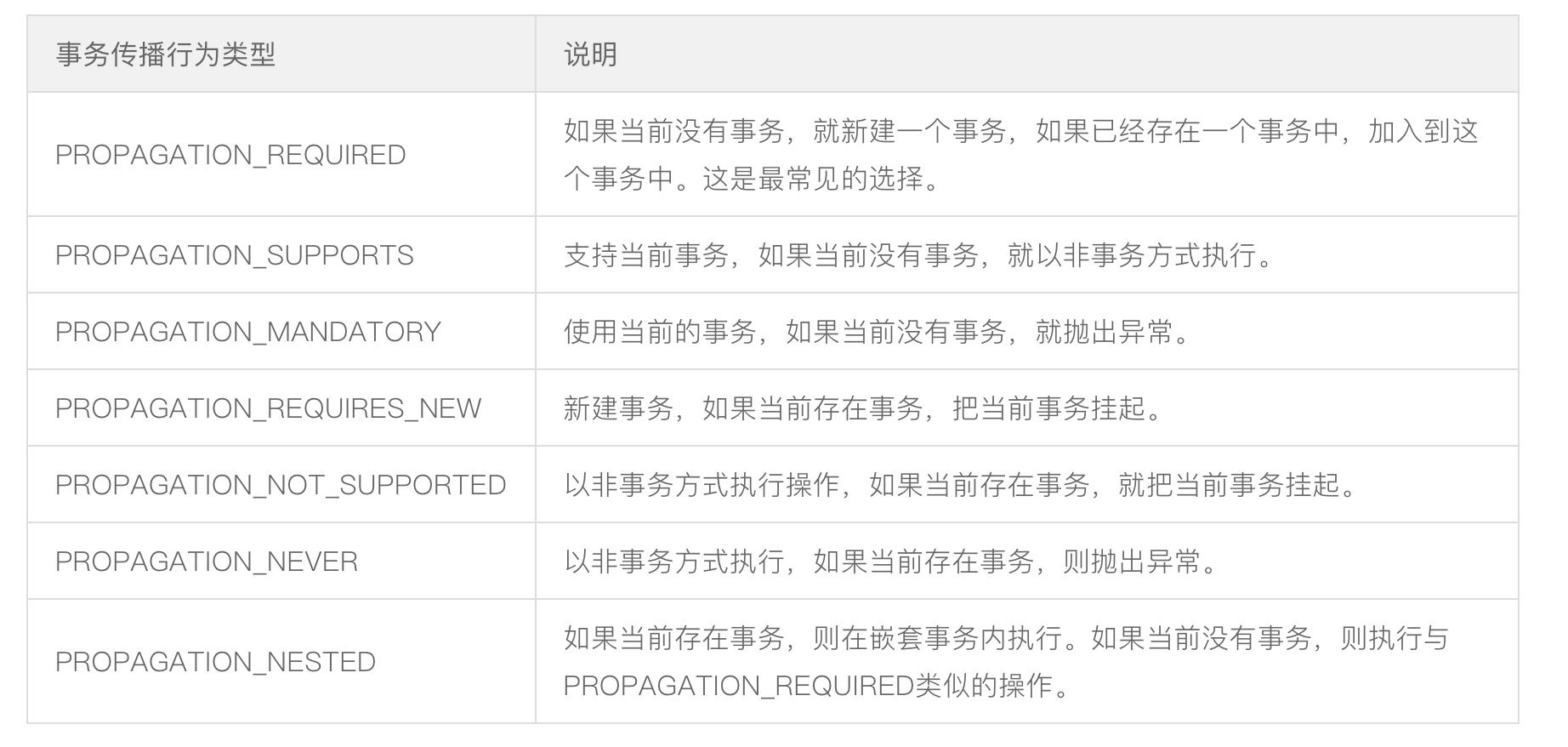
事务的传播性
- PROPAGATION_NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于
TransactionDefinition.PROPAGATION_REQUIRED。(比如我们设计ServiceA.methodA的事务级别为PROPAGATION_REQUIRED,ServiceB.methodB的事务级别为PROPAGATION_NESTED,那么当执行到ServiceB.methodB的时候,ServiceA.methodA所在的事务就会挂起,ServiceB.methodB会起一个新的子事务并设置savepoint,等待ServiceB.methodB的事务完成以后,他才继续执行。) - PROPAGATION_REQUIRED:支持当前事务,如果不存在则创建新事务。(方法B已经运行在方法A的事务内部,就不再起新的事务,直接加入方法A)。
- RROPAGATION_REQUIRES_NEW:创建一个新事务,并暂停当前事务(如果存在)。(方法A所在的事务就会挂起,方法B会起一个新的事务,方法B新起的事务不依赖方法A的事务,等待方法B的事务完成以后,方法A才继续执行,如果方法B执行没有异常,方法A抛出异常,方法B的操作不会被回滚,方法A中除了方法B外,会回滚数据)。
- PROPAGATION_SUPPORTS:如果当前存在事务中,即以事务的形式运行;如果不存在则以非事务方式执行。(方法B看到自己已经运行在方法A的事务内部,就不再起新的事务,直接加入方法A)
- PROPAGATION_NOT_SUPPORTED:支持当前事务,如果不存在则创建新事务。(方法A所在的事务就会挂起,而方法B以非事务的状态运行完,再继续方法A的事务)。
- PROPAGATION_MANDATORY:支持当前事务,如果有,使用当前事务;如果不存在则抛出异常。
- PROPAGATION_NEVER:如果事务存在,则以非事务方式执行,抛出异常。(假设ServiceA.methodA的事务级别是PROPAGATION_REQUIRED, 而ServiceB.methodB的事务级别是PROPAGATION_NEVER ,那么ServiceB.methodB就要抛出异常了。)
下面给出一张图,对上面的事务传播性,做出总结:
事务的隔离性
事务并发可能引起的问题:
脏读:脏读发生在一个事务读取了另一个事务改写但尚未提交的数据时。如果改写在稍后被回滚了,那么第一个事务获取的数据就是无效的;
不可重复读:不可重复读发生在一个事务执行相同的查询两次或两次以上,但是每次都得到不同的数据时。这通常是因为另一个并发事务在两次查询期间进行了更新;
幻读:幻读是由“可重复读”隔离级别导致的事务问题。事务T1查询某条数据,发现数据库没有数据,同时事务T2也查询这条数据,也同样没查询到。这时T1就将数据插入到了数据,由于可重复读的隔离级别,所以T2还是查询不到这条数据,然后T2插入了同样的数据,然后提示说数据以及存在,但是在事务T2中有查询不到这条数据,就像出现幻觉一样。