Redis系列:
Redis是一款NoSQL数据库,在大多数项目中作为缓存使用,也可以作为数据库,存储数据。
数据库
Redis服务器将所有数据库都保存在服务器状态 redis.h/redisServer 结构的 db 数组中,db 数组的每个项都是一个 redis.h/redisDb结构,每个 redis 结构代表个数据库:
1 | struct redisServer { |
键空间和用户所见的数据库是直接对应的:
- 键空间的键也就是数据库的键,每个键都是一个字符串对象。
- 键空间的值也就是数据库的值,每个值可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象中的任意一种 Redis 对象。
过期键删除策略
定时删除:在设置键的过期时间的同时,创建一个定时器( timer),让定时器在键的过期时间来临时,立即执行对键的删除操作。这种策略对内存友好,但是对CPU时间是最不友好的:在过期间比较多的情况下,删除过期键这一行为可能会占用箱单大一部分CPU时间,影响服务器的响应时间和吞吐量。
惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。这种策略是对内存很不友好,如果一些过期键,一直没被查找,就会一直占用内存,可能会出现内存泄露的危险。
定期删除:每隔一段时间,程序就对数据库进行一次检査,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定
在这三种策略中,第一种和第三种为主动删除策略,而第二种则为被动删除策略。
Redis 服务器实际使用的是惰性删除和定期删除两种策略:通过配合使用这两种删除策略,服务器可以很好地在合理使用CPU时间和避免浪费内存空间之间取得平衡。
Redis 内存淘汰机制
Redis 提供了6种数据淘汰策略:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
4.0 版本后增加了以下两种:
- volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
- allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
Redis 持久化
RDB (Redis DataBase) 持久化
因为 Redis 是内存数据库,它将自己的数据库状态储存在内存里面,所以如果不想办法将储存在内存中的数据库状态保存到磁盘里面,那么一且服务器进程退出,服务器中的数据库状态也会消失不见。为了解决这个问题,Redis 提供了 RDB 持久化功能,可以将 Redis 在内存中的数据库状态保存到磁盘中,避免数据丢失。RDB是一个经过压缩的二进制文件。

Redis 有两个命令用来自生成 RDB 文件:SAVE 和 BGSAVE。
- SAVE:当 save 执行是,Redis服务器会被阻塞,客户端发送的所有命令请求都会被拒绝。
- BGSAVE:Redis 进程执行 fork 操作创建子进程,所以 Redis 服务器可以继续执行客户端的命令。
在 Redis 涉及 RDB 的操作都采用 BGSAVE 的方式,而 SAVE 命令已经废弃。
RDB文件结构

RDB文件的最开头是 REDIS 部分,这个部分的长度为5字节,保存着 REDIS 五个字符。通过这五个字符,程序可以在载入文件时,快速检查所载人的文件是否RDB文件。
db version 长度为 4字节,它的值是一个字符串表示的整数,这个整数记录了RDB文件的版本号,比如”0006就代表RDB文件的版本为第六版。本章只介绍第六版 RDB 文件的结构。
databases 部分包含着零个或任意多个数据库,以及各个数据库中的键值对数据:
- 如果服务器的数据库状态为空(所有数据库都是空的),那么这个部分也为空,长度为0字节。
- 如果服务器的数据库状态为非空(有至少一个数据库非空),那么这个部分也为非空,根据数据库所保存键值对的数量、类型和内容不同,这个部分的长度也会有所不同。
EOF常量的长度为1字节,这个常量标志着RDB文件正文内容的结束,当读入程序遇
这个值的时候,它知道所有数据库的所有键值对都已经载入完毕了。
check sum 是一个8字节长的无符号整数,保存着一个校验和,这个校验和是程序通过对 REDIS、 db version、 databases、EoF四个部分的内容进行计算得出的。服务器在载入RDB文件时,会将载入数据所计算出的校验和与 check sum所记录的校验和进行对比,以此来检查RDB文件是否有出错或者损坏的情况出现。
RDB 快照的过程如下:
- Redis使用fork函数复制一份当前进程(父进程)的副本(子进程);
- 父进程继续接收并处理客户端发来的命令,而子进程开始将内存中的数据写入硬盘中的临时文件;
- 当子进程写入完所有数据后会用该临时文件替换旧的 RDB 文件,至此一次快照操作完成。
Copy-On-Write 机制
核心思路:fork 一个子进程,只在父进程发生写操作修改内存数据时,才会真正去分配内存空间,并复制内存数据,而且也只是复制被修改的内存页中的数据,并不是全部内存数据,所以新的RDB文件存储的是执行 fork 那一刻的内存数据。
- Redis中执行BGSAVE命令生成RDB文件时,本质就是调用Linux中的fork()命令,Linux下的fork()系统调用实现了
Copy-On-Write写时复制; - fork()是类Unix操作系统上创建线程的主要方法,fork用于创建子进程(等同于当前进程的副本);
- 传统的普通进程复制,会直接将父进程的数据拷贝到子进程中,拷贝完成后,父进程和子进程之间的数据段和堆栈是相互独立的;
Copy-On-Write技术,在fork出子进程后,与父进程共享内存空间,两者只是虚拟空间不同,但是其对应的物理空间是同一个。
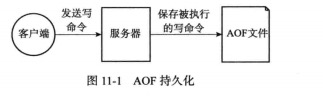
AOF 持久化
AOF 持久化是通过保存 Redis 服务器所执行的写命令来记录数据库状态的,查询操作不会记录,AOF 命令写入的内容直接是文本协议格式,在重启时在执行 AOF 文件中的命令达到恢复数据的目的。
AOF 的主要作用是解决数据持久化的实时性,目前已经是 Redis 持久化的主流方式。
1 | redis> SET msg "hello" |
对于RDB持久化存储的是SET、PUSH这两个键值对;AOF持久化存储的是SET、PUSH这两个命令。
AOF 重写
Redis 在长期运行的过程中,AOF 的日志会越变越长。如果实例宕机重启,重放整个 AOF 日志会非常耗时,导致长时间 Redis 无法对外提供服务。所以需要对 AOF 日志 “瘦身”。
Redis 提供了 bgrewriteaof 指令用于对 AOF 日志进行瘦身。其原理就是开辟一个子进程对内存进行遍历转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件中。序列化完毕后再将操作期间发生的增量 AOF 日志追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件了,瘦身工作就完成了。
fsync
AOF 日志是以文件的形式存在的,当程序对 AOF 日志文件进行写操作时,实际上是将内容写到了内核为文件描述符分配的一个内存缓存中,然后内核会异步将脏数据刷回磁盘中。
Redis 提供2中策略
- 永不 fsync : 让操作系统来决定适合同步磁盘
- fsync : 使用 fsync 紫菱,Redis 每个1秒执行一次 fsync 命令
RDB 和 AOF 比较
RDB 持久化优缺点
RDB 持久化优点:
- 使用 RDB 持久化,整个 Redis 数据库将只包含一个文件,这对于文件备份而言非常完美
- 对于灾难恢复而言,RDB 是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上。
- 性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork出子进程,之后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。
- 相比于 AOF 机制,如果数据集很大,RDB的启动效率会更高
RDB 持久化缺点:
- 如果想保证 Redis 数据的高可用性,即最大限度的避免数据丢失,RDB 不是一个好的选择。在 Redis 定时持久化之前出现宕机现象,就不能保证数据及时写入磁盘中。
- 由于 RDB 是通过 fork 子进程来协助完成数据持久化工作,当数据集比较大的时候,可能导致整个服务器停止服务操作。
AOF 持久化优缺点
AOF 持久化优点:
- 该方法保证了数据的安全性。Redis 中提供了3种同步策略,即每秒同步、每修过同步和不同步。每秒同步是异步完成的,其效率是非常高的,其缺点是出现宕机时,这一秒内修改的数据会丢失;每修改同步,可以看做为同步持久化,即每次数据发生变化时,就记入到磁盘中,这种同步方法性能相对比较低;不同步就是字面的意思。
- 该机制对日志文件的写入操作采用的是 append 模式,因此即使在写入过程中出现宕机现象,也不会破坏之前的日志文件内容。如果本次操作只是写入了一半数据就出现了系统崩溃问题,不需要担心数据丢失,在Redis下一次启动之前,我们可以通过redis-check-aof 工具来帮助我们解决数据一致性的问题。
- 如果日志过大,Redis 可以自动启用 rewrite 机制。即 Redis 以 append 模式不断的将修改数据写入到老的磁盘文件中,同时 Redis 还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行 rewrite 切换时可以更好的保证数据安全性。
- AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
AOF 持久化缺点:
- 对于相同数量的数据集而言,AOF 文件通常要大于 RDB 文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
- 根据同步策略的不同,AOF 在运行效率上往往会慢于 RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和 RDB 一样高效。
总结
对于持久化的选择,主要看系统是愿意牺牲一些性能,换取更高的缓存一致性(AOF),还是愿意写操作频繁的时候,不启动被封换取高性能,手动运行备份(RDB)。
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
事件
Redis 服务器是一个事件驱动程序,服务器需要处理以下两类事件:
- 文件事件(file event): Redis服务器通过套接字与客户端(或者其他 Redis服务器)进行连接,而文件事件就是服务器对套接字操作的抽象。服务器与客户端(或者其他服务器)的通信会产生相应的文件事件,而服务器则通过监听并处理这些事件来完成一系列网络通信操作。
- 时间事件(time event): Redis服务器中的一些操作(比如 servercron函数)需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象。
文件事件
Redis 基于Reactor模式开发了自己的网络事件处理器即文件事件处理器。
文件事件处理器使用I/O多路复用程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事务处理器。
时间事件
Redis的时间事件分为以下两类:
- 定时事件:让一段程序在指定的时间之后执行一次。比如说,让程序X在当前时间的30毫秒之后执行一次。
- 周期性事件:让一段程序每隔指定时间就执行一次。比如说,让程序Y每隔30毫秒就执行一次。
一个时间事件的三个属性:
- ID:服务器为时间事件创建的全局唯一ID。
- when:毫秒精度的UNX时间戳,记录了时间事件的到达( arrive )时间。
- timeproc:时间事件处理器,一个函数。当时间事件到达时,服务器就会调用相应的处理器来处理事件。
服务器把所有时间事件都放在一个无序链表中,每当时间事件执行,遍历整个链表,查找所有已达的时间事件,并调用相应的事件处理器。
服务器
命令请求过程:
- 客户端向服务器发送请求命令:Redis服务器的命令请求来自Reds客户端,当用户在客户端中键入一个命令请求时,客户端会将这个命令请求转换成协议格式,然后通过连接到服务器的套接字,将协议格式的命令请求发送给服务器。
- 服务器接收并处理客户端发来的命令请求,在数据库中进行设置操作,并尝试命令回复OK
- 读取套接字中协议格式的命令请求,并将其保存到客户端状态的输入缓冲区里面。
- 对输入缓冲区中的命令请求进行分析,提取出命令请求中包含的命令参数,以及命令参数的个数,然后分别将参数和参数个数保存到客户端状态的 argv 属性和 argc 属性里面
- 调用命令执行器,执行客户端指定的命令
- 服务器将命令回复OK发送给客户端
- 客户端接收到服务器的返回的命令OK,并打印显示在客户端

