消息中间件的作用
消息中间件的作用可以概括如下:
- 解耦:消息中间件在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要事先这一接口,这允许你独立地扩展或修改两边的处理过程,只要确保他们遵守同样的接口约束即可。
- 冗余(储存):有些情况下,处理数据的过程会失败。消息中间件可以把数据持久化直到它们已经完全处理,通过这一范式规避了数据丢失风险。
- 扩展性:因为消息中间件解耦了应用的处理过程,所以提高了消息入队和处理的效率和容易的,只要另外增加处理过程即可,不需要改变代码,也不需要调节参数。
- 消峰:在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。使用消息中间件能够使关键组件支撑突发访问压力,不会因为突发的超负荷请求而完全崩溃。
- 可恢复性:即使一个处理消息的进程挂掉,加入消息中间件中的消息仍然可以在系统恢复后进行处理。
- 顺序保证:消息中间件支持一定程度上的顺序性
- 缓冲:消息中间件通过一个缓冲层来帮助任务最高效率的执行,写入消息中间件的处理会尽可能快速。该缓冲层有助于控制和优化数据流经过系统的速度。
- 异步通信:消息中间件提供了异步处理机制。
AMQP
AMQP,即 Advanced Message Queuing Protocol,一种提供统一消息服务的应用层标准高级
消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端和消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开放语言等条件的限制。基于此协议的消息中间件有RabbitMQ。
各种MQ的比较
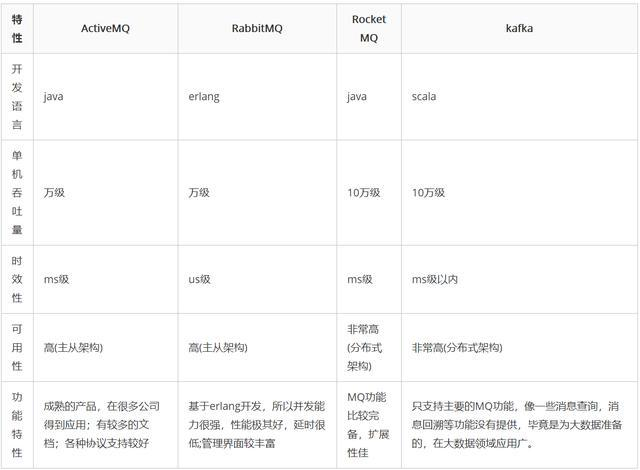
目前业界有很多MQ产品,比如 RabbitMQ、RocketMQ、Kafka、ActivceMQ等。其中ActiceMQ现在社区活跃度不是很高,已经被很多人弃用了。其中RabbitMQ 是基于erlang语言的,虽然其实开源的,但是如果需要定制化的话,维护是一件很麻烦的事情。Kafka 和 RocketMQ ,前者是Scala,后者是阿里出品的,基于Java开发的。所以,我们一般选择MQ的时候,主要从RabbitMQ、Kafka、RocketMQ这几个主流MQ中选择一个适合的。
Kafka
Kafka 主要定位在日志等方面,因为Kafka 设计的初衷就是为了处理日志。
优点
- 性能卓越,单机写入TPS约在百万条/秒,最大的优点,就是吞吐量高。
- 时效性:ms级
- 可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用
- 消费者采用Pull方式获取消息, 消息有序, 通过控制能够保证所有消息被消费且仅被消费一次;
- 有优秀的第三方Kafka Web管理界面Kafka-Manager;
- 在日志领域比较成熟,被多家公司和多个开源项目使用;
- 功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用
缺点
- Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长
- 使用短轮询方式,实时性取决于轮询间隔时间;
- 消费失败不支持重试;
- 支持消息顺序,但是一台代理宕机后,就会产生消息乱序
RabbitMQ
RabbitMQ 结合 erlang 语言本身的性质,高并发,高可用等特性。
优点
- 由于erlang语言的特性,mq 性能较好,高并发
- 吞吐量到万级,MQ功能比较完备
- 健壮、稳定、易用、跨平台、支持多种语言、文档齐全
缺点
- erlang 语言开放,比较难维护
- RabbitMQ的吞吐量相对另外两个MQ低很多
RocketMQ
RocketMQ 适合互联网金融领域,支持可靠性要求高的场景。
优点
- 单机吞吐量:十万级
- 可用性:非常高,分布式架构
- 消息可靠性:经过参数优化配置,消息可以做到0丢失
- 功能支持:MQ功能较为完善,还是分布式的,扩展性好
- 支持10亿级别的消息堆积,不会因为堆积导致性能下降
缺点
- 支持的客户端少

