欢迎指正。
索引的一些基本认知:
- 索引可以加快数据库的检索速度
- 表经常进行INSERT/UPDATE/DELETE操作就不要建立索引了,换言之:索引会降低插入、删除、修改等维护任务的速度。
- 索引需要占物理和数据空间。
- 了解过索引的最左匹配原则
- 知道索引的分类:聚集索引和非聚集索引
- MySQL 支持Hash索引和B+树索引两种
索引的基础知识
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间 (因为索引也要随之变动)。
创建索引可以大大提高系统的性能。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 可以加速表和表之间的连接,
- 使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
创建索引的原则
创建索引的一些原则:
- 较频繁的作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合创建索引(数据库会将索引数据根据算法排序,数据量大之后重新排序会占用过多资源)
- 用于索引的最好的备选数据列是那些出现在WHERE子句、join子句、ORDER BY或GROUP BY子句中的列。
MySQL 存储结构
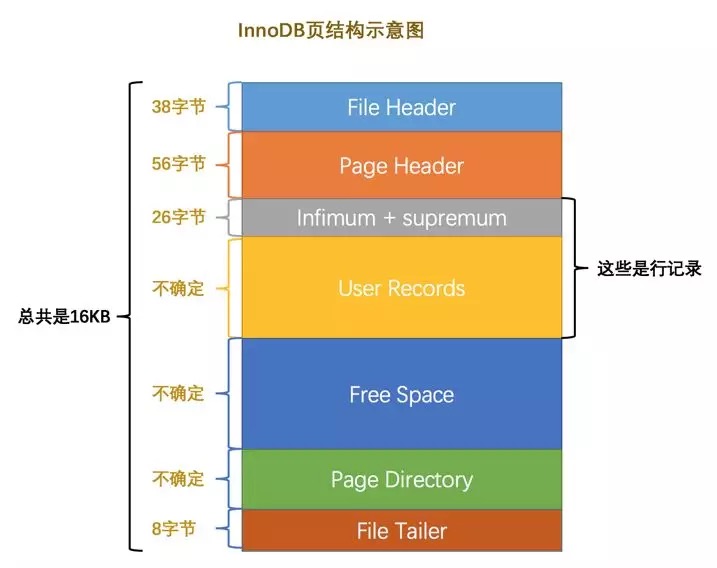
MySQL的基本存储结构是页,一页的大小一般是16KB。
- 各个数据页可以组成一个双向链表
- 每个数据页中的记录可以组成单向链表
InnoDB 表
在InnoDB存储引擎中,表都是根据主键顺序组织存放的。在InnoDB存储引擎表中,每张表都有个主键,如果在创建表的时没有显式地定义主键,InnoDB存储引擎会按照下面选择或者创建主键:
- 首先判断表中是否有非空的唯一索引,如果有,则该列即为主键(如果有多个的时候,选择第一个定义的唯一索引);
- 如果不符合上述条件,InnoDB存储引擎自动创建一个6字节大小的指针。
注意: 在建表的时候,最好还是指定主键,而且最好使用自增,而不是UUID这种作为主键,因为UUID一般都是无序的,在插入新的记录的时候,可能增加额外的开销。B+树为了维护索引的有序性,在插入新值得实惠需要做必要的维护。比如在某页数据中间插入某条数据,这时候就需要移动后面的数据,空出位置。如果碰到这一页数据满了,还需要申请新的数据页,挪动部分数据过去,这种过程称为页的分裂,这种情况就很影响性能。
索引提高检索速度
索引用于快速查找具有特定列值的行。如果没有索引,MySQL必须从第一行开始,然后读取整个表以查找相关行。表越大,成本越高。如果表中有相关列的索引,MySQL可以快速确定要在数据文件中间寻找的位置,而无需查看所有数据。这比按顺序读取每一行要快得多。
如果没有索引
在一个页里查找
如果表中数据现在比较少,都存放在一个页里,在查找的时候按照不同省市条件查找:
- 主键:在 页目录 中使用二分法快速定位到相应的槽,然后在遍历该槽对应分组即可查找到数据
- 其他列:只能从最小记录开始依次遍历单链表中的每条记录,然后对比每条记录是不是符合搜索条件
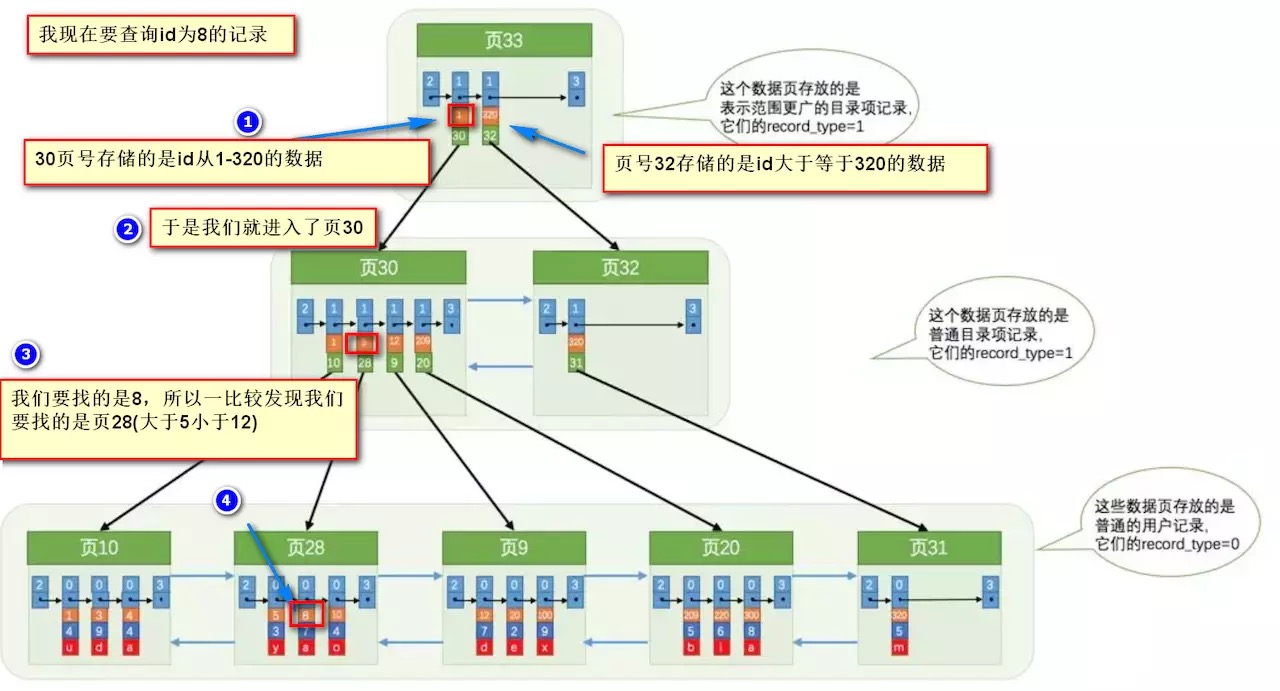
多页中查找
- 先定位到数据所在的页;
- 在从页中查找相应的数据。
使用索引
将无序的数据变成有序(相对)。
索引数据结构
B-Tree 索引
B-Tree 是一棵多叉树,在非叶子节点中存储了数据。
B+ Tree索引
该索引使用 B+Tree 数据结构来存储数据,B+Tree 是InnoDB存储引擎默认的索引结构。
B+ Tree 是 B-Tree 的变种,通常意味着所有数据值都是按照顺序存储的,并且每一个叶子页到根的距离相同。存储引擎不需要进行全表扫描来获取需要的数据,只需要从索引节点进行搜索。索引的叶子节点之间通过索引互相连接。
哈希索引
基于哈希表实现,只有精确匹配索引所有列的查询才有效。
1 | mysql> select * from table where name = 'Peter' |
MySQL先会计算 ‘Peter’ 的哈希值,并使用该值寻找对应的记录指针。
哈希索引的限制:
- 不能使用索引中的值来避免读取行
- 不能按照索引顺序存储,所以无法用于排序
- 不支持部分索引列匹配查询
- 只支持等值查询,包括 =、in()、<=>
InnoDB 为什么选择 B+Tree 作为默认索引结构
- 哈希虽然能够提供 O(1) 的单数据行操作性能,但是对于范围查询和排序却无法很好地支持,最终导致全表扫描;
- B-Tree 能够在非叶节点中存储数据,但是这也导致在查询连续数据时可能会带来更多的随机 I/O,而 B+Tree 的所有叶节点可以通过指针相互连接,能够减少顺序遍历时产生的额外随机 I/O。
常见索引类型
聚簇索引
聚簇索引指主索引文件和数据文件为同一份文件,聚簇索引主要用在 InnoDB 存储引擎中。在该索引实现方式中,B+ Tree 的叶子节点上的data就是数据本身,key为主键,如果是一般索引的话,data便会指向对应的主索引。一张表也不可能有两个地方存储数据,所以一张表只能有一个聚簇索引。
InnoDB 表中聚簇索引的索引列就是主键,所以聚簇索引也叫主键索引。
非聚簇索引
非聚簇索引指的是 B+Tree 的叶节点上的data,并不是数据本身,而是数据存放的地址。主索引和辅助索引没啥区别,只是主索引的key一定是唯一的。主要用于MyIsAM存储引擎中。
非聚簇索引比聚簇索引多了一次读取数据的IO操作,索引查找性能上会差。
二级索引
对于 InnoDB 表,在非主键的其他列上建的索引就是二级索引。
按照字段列分类
MySQL的索引分为单列索引(主键索引,唯一索引,普通索引)和组合索引(或叫联合索引)
- 单列索引:一个索引只包含一个列,一个表可以有多个单列索引
- 组合索引:一个组合索引包含两个或两个以上的列。从左到右
索引使用的基本常识
注意点
使用索引时的一些注意点:
- 符合最左原则
- 如果是or,不走索引
- 数据区分度不大的字段不宜使用索引
- MySQL从左到右的使用索引中的字段,一个查询可以使用索引中的一部分,但只能是最左侧部分。例如索引是key index(a,b,c),可以支持a|a,b|a,b,c 3种组合进行查询,但不支持b,c进行查找。当最左侧字段是常量引用时,索引就十分有效。
索引的优点
- 索引大大减少了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机 I/O 变为顺序 I/O
最左匹配原则
- 索引可以简单如一个列 (a),也可以复杂如多个列 (a,b,c,d),即联合索引。
- 如果是联合索引,那么key也由多个列组成,同时,索引只能用于查找key是否存在(相等),遇到范围查询 (>、<、between、like左匹配)等就不能进一步匹配了,后续退化为线性查找。
- 因此,列的排列顺序决定了可命中索引的列数。
比如,现在有索引 (a,b,c,d),查询条件 a=1 and b=2 and c>3 and d=4,则会在每个节点依次命中a、b、c,无法命中d。(c已经是范围查询了,d肯定是排不了序了)。
回表和覆盖索引
回表
在InnoDB中,对于普通索引的查询,是无法直接定位行记录的。普通索引需要先定位到对象的主键,然后通过主键去查询数据。这种查询相对于聚簇索引来说,多了一次查询。
覆盖索引
覆盖索引是一种避免回表查询的优化策略。具体的做法是将查询的数据作为索引列建立普通索引,这样就可以直接返回索引中的数据,而不需要通过聚簇索引去定位行记录,避免回表的发生。
索引下推
最左前缀可以用于在索引中定位记录。现在我们有一个联合索引(name, age),现在需要查询下面这个SQL:
1 | select * from table where name like "张%" and age = 10 |
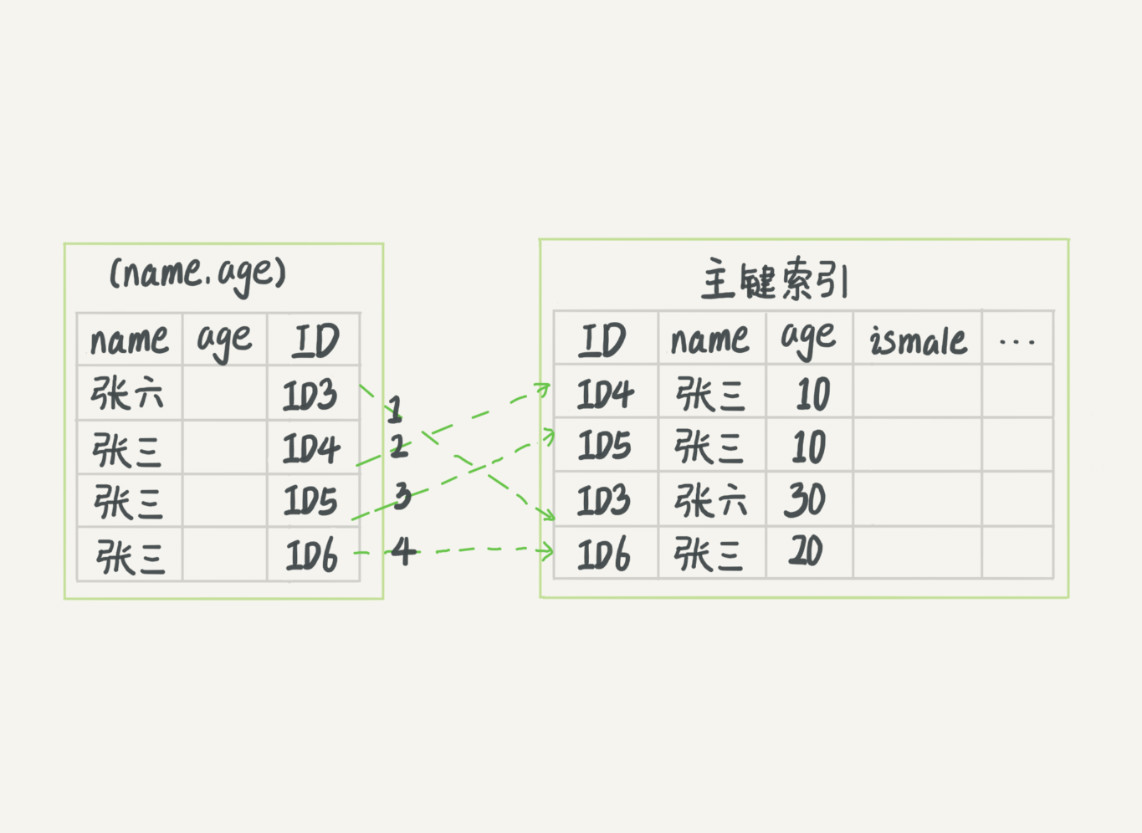
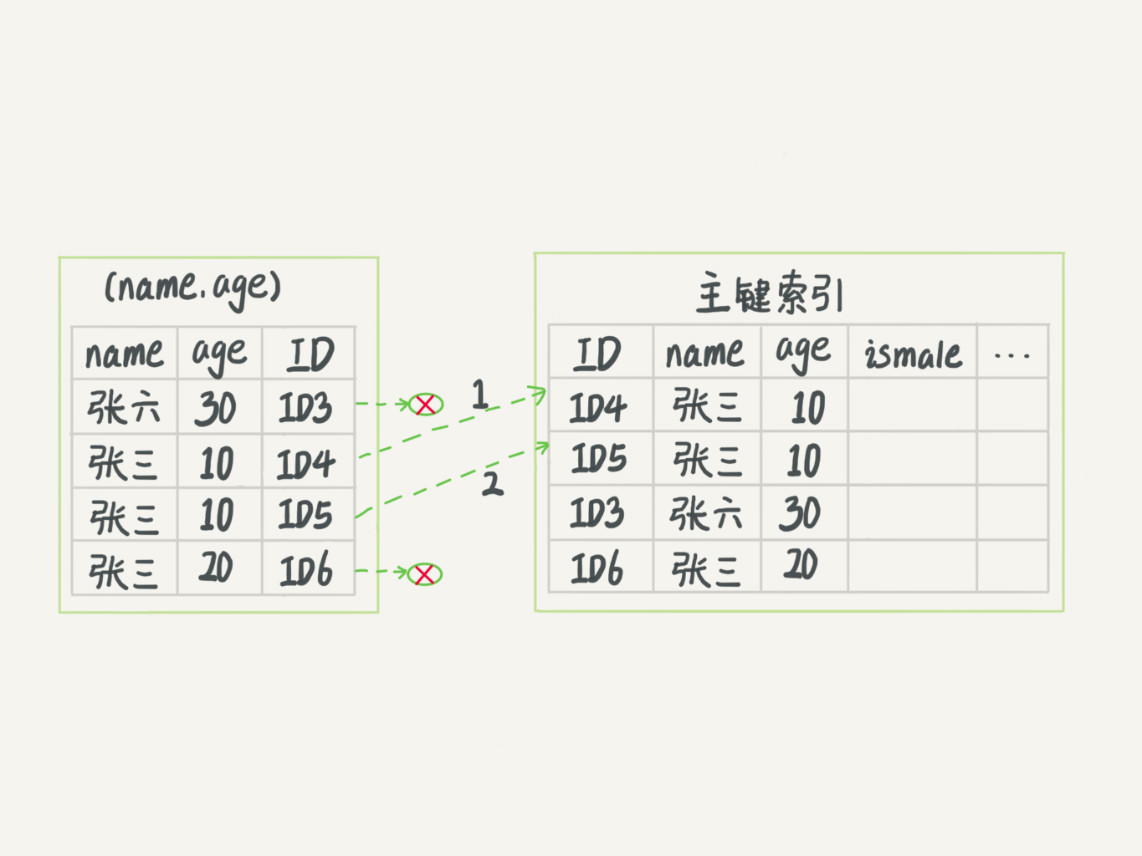
使用前缀索引规则是,只能用“张”,找到第一个满足条件的记录,然后在一个个回表查询数据行。MySQL 引入索引的下推优化(index condition pushdown),可以在索引遍历中,对索引包含的字段现做判断,直接过滤掉不满足的记录,减少回表次数。如下图所示,第一个图是吴索引下推的流程,第二张图,则是进行了索引下推优化,减少了回表次数。
=、in自动优化顺序
对于注意点最后一点,在MySQL中,对于索引会自动优化条件的顺序,方便匹配尽可能对的索引列。可以看下面一个实例:
1 | CCREATE TABLE `user` ( |
如上面创建一张表,并创建索引 idx_user。
1、从上面的一个例子,我们可以看出,虽然我们查询条件并没有按照索引里面的顺序,但是查询还是走的是索引。


2、这个例子看出,下面这个查询没有走索引。可以注意点最后一点对照着看。


关于IN是否走索引
1 | EXPLAIN SELECT * FROM `user` WHERE age IN (5,6,18,19) |


