声明:如果本文有错误,希望指出。
在之前的一篇博文中简单介绍了 Java 中的一些锁:Java 中各种锁。
最近在极客时间上买了杨晓峰的《Java核心技术36讲》,今天看到关于标题的东西,于是想记录下自己的学习。
Synchronized 和 ReentrantLock 这两个都是可重入锁,指的是同一线程在外层函数获取锁之后,内层函数仍然可以获取该锁,且不受影响。
Synchronized 锁的原理
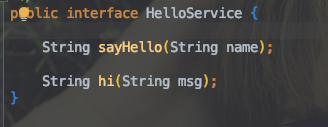
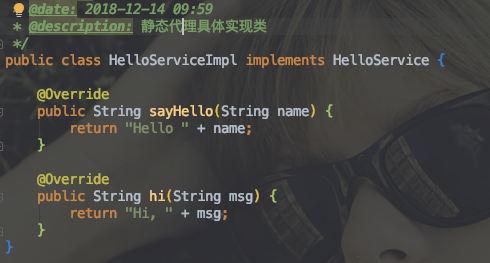
1 | public class SynchronizedTest { |
使用javac SynchronizedTest.java 和 javap -c -s -v -l SynchronizedTest 命令查看编译后的Test.class的字节码,可以很容易看出在代码块上和方法上是有区别的。代码块上使用 monitorenter/monitorexit 指令来实现的;方法上是使用 ACC_SYNCHRONIZED。详情看下面的图片,是编译后的字节码:
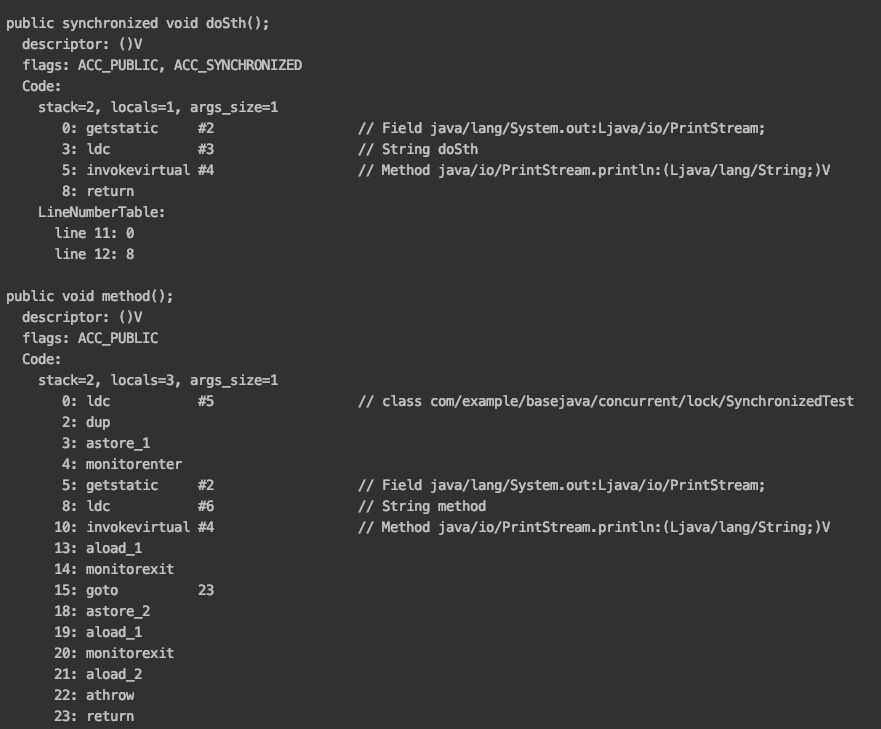
在 Java6 之前,Monitor 的实现完全是依靠操作系统内部的互斥锁,因为需要用户状态到内核状态的切换,所有同步操作是一个重量级操作。
Synchronized 底层原理,Synchronized 有2个队列 waitSet 和 entrtyList。
- 当多个线程进入同步代码块时,首先进入entryList
- 有一个线程获取到monitor锁后,就赋值给当前线程,并且计数器+1
- 如果线程调用wait方法,将释放锁,当前线程置为null,计数器-1,同时进入waitSet等待被唤醒,调用notify或者notifyAll之后又会进入entryList竞争锁
- 如果线程执行完毕,同样释放锁,计数器-1,当前线程置为null